



 教育インタビュー
教育インタビュー 新刊紹介
新刊紹介 教材紹介
教材紹介



意外と知らない"テスト理論"(第2回) ~古典的テスト理論の限界点とIRT(項目反応理論)~

第1回では、よいテストとは何か?について、古典的テスト理論の観点から考えていきました。今回はより新しいテスト理論である「項目反応理論(IRT:Item Response Theory)」について紹介します。最近、活用される機会が多くなってきたIRT。教育に関心がある方なら、耳にしたことがあるという方も多いのではないでしょうか。第2回では、前回紹介した古典的テスト理論の限界点とIRTの特徴やその活用例について紹介していきます。
6.古典的テスト理論の限界点
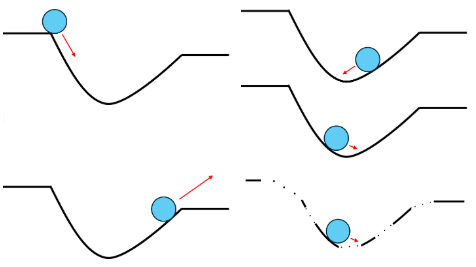
前回のテストよりいい点数だったら、喜んでいい?
第1回で紹介した古典的テスト理論は、現在でも多くのテストや非認知能力などの心理尺度(アンケート調査の質問項目)の開発で応用されています。しかし、以下に述べる限界点が指摘されています。
限界点①:項目依存性
下記の学力調査を用いた例について考えてみましょう。
「毎年異なった問題を出題する学力調査を2年連続で実施したA中学校。去年の調査では平均点が50点でしたが、今年の調査では平均点が70点でした。」
上述の例の場合、A中学校の生徒の学力が伸びたとはいえるでしょうか。答えはNoです。なぜなら、問題の困難度(難しさ)が異なるからです。今年の問題より、去年の問題の方が難しかった場合、去年の生徒の学力の方が高かった可能性があります。このように異なるテストを比較することができません。このことを、テスト得点の項目依存性(item dependence)といいます。
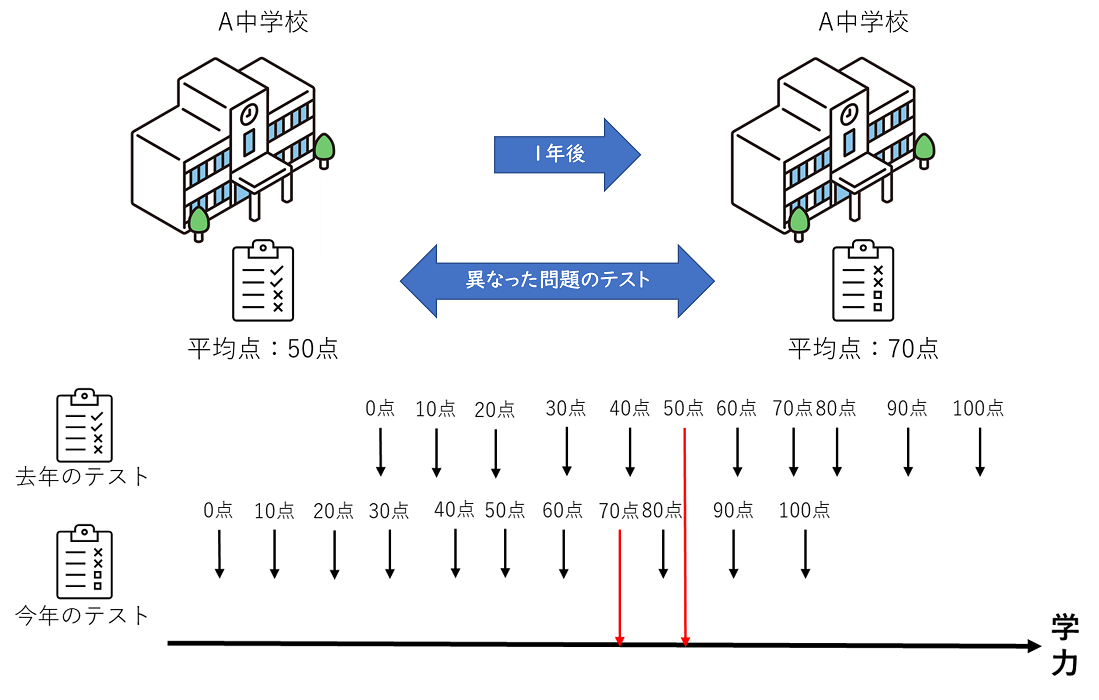
(宇佐美慧・荘島宏二郎・光永悠彦・登藤直弥 (2019)を参考に作成)
限界点②:標本依存性
では、困難度が同じである学力調査では問題ないのでしょうか。下記の例を考えてみましょう。
「困難度が統制された学力調査を受験したA中学校のXさんの校内偏差値は50、B中学校のYさんの校内偏差値は60でした。」
この場合、Xさんに比べ、Yさんの学力が高いといえるでしょうか。答えはNoです。なぜなら、受験者集団の能力が異なるからです。A中学校の多くの生徒の学力が高く、B中学校の多くの生徒の学力が低い場合、Xさんの学力が高かった可能性があります。このように異なる受験者集団を比較することができません。このことをテスト得点の標本依存性(sample dependence)といいます。
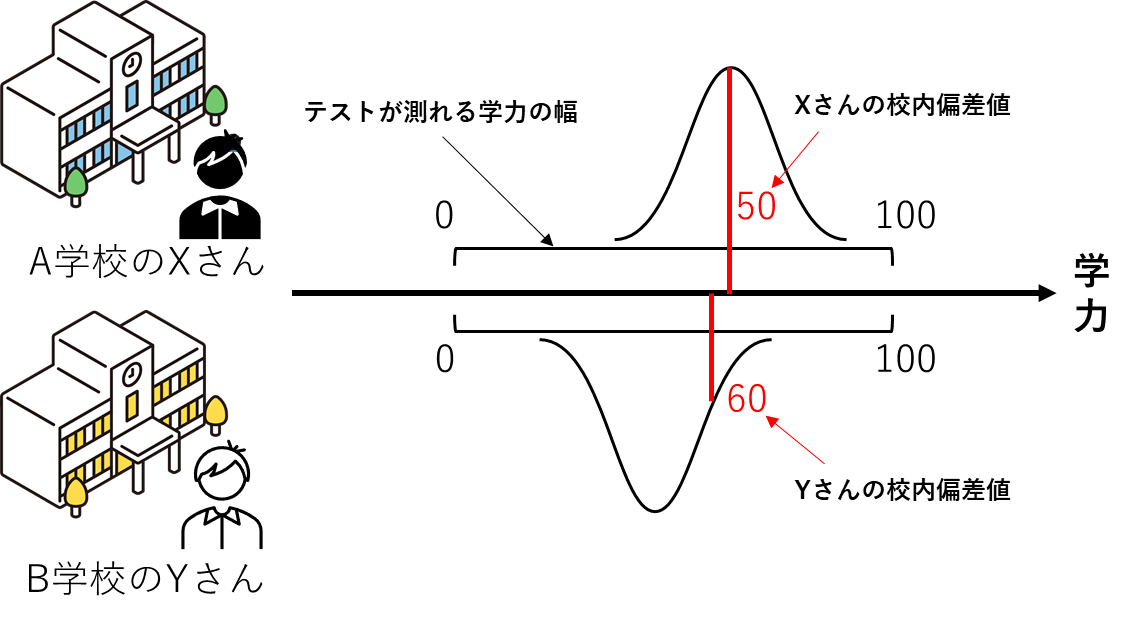
(宇佐美慧・荘島宏二郎・光永悠彦・登藤直弥 (2019)を参考に作成)
上述の例はいずれも古典的テスト理論の限界点といえます。つまり、異なった受験者集団を比較したり、異なったテストを比較したりすることができません。
7.項目反応理論(IRT)の活用例
このような限界点を解決するために、1950年代ごろから発展を重ねてきた新しいテストの質の評価方法として、項目反応理論(IRT:Item Response Theory)があります。まずは、実際にIRTが活用されている試験の例を見ていきましょう。身近なものとして、ETSが実施する英語のテストであるTOEFLが挙げられます。
TOEFLは1年のうちに30回以上の受験機会があります。各回のテストは異なる問題から構成されており、受験者集団も異なります。しかし、皆さんもご存じのように、フィードバックされるスコアは同じ得点であれば同じ能力であると考えることができます。これはまさしくIRTを活用し、項目依存性と標本依存性を解決しているからこそといえるでしょう。
他にも、様々なテストで活用されています。以下にいくつかの試験を紹介します。
○IRTが活用されている試験例
- 情報処理技術者試験 (経産省・(独)情報処理推進機構情報処理技術者試験センター)
- 医療系大学共用試験 (医療系大学間共用試験実施評価機構)
- 日本留学試験 (日本国際教育協会 AIEJ→日本学生支援機構 JASSO)
- 日本語能力試験 (国際交流基金・公益法人日本国際教育支援協会)
- JETRO ビジネス能力日本語試験 (日本貿易振興機構 JETRO→漢検)
また、近年ではIRTを活用する学力調査も増えてきました。例えば、埼玉県学力・学習状況調査では、平成27年度からIRTを活用することにより、「児童生徒一人ひとりの学力がどれだけ伸びているのか」を測ることができる調査を実施しています。また、横浜市学力・学習状況調査においても、令和5年度からの導入が発表されています。
さらにコンピュータでテストを受けると、正誤によって次に出題する問題を変更することも可能です。今後、IRT分析結果に基づいて、受験者の能力に近いレベルの問題だけ出題すること(アダプティブテスト)で、従来の方法よりも短い時間で、精度の高い能力推定値を算出できるようになることも期待されています。
8.項目反応理論(IRT)の枠組み
それでは項目反応理論(IRT)の理論的な枠組みについても少し触れてみましょう。IRTの大きな特徴は、テストに含まれる項目(各問題)の困難度(難しさ)と受験者の能力を別々に推定し、同じものさしの上で評価できる点にあります。このことは下図のような曲線、項目反応曲線(ICC:Item Characteristic Curve)を用いることにより実現されます。横軸に潜在的に仮定された「能力値」をとり、対応する期待正答確率を縦軸にとり、受験者の正誤データから、項目1つひとつについて項目反応曲線を推定します。
このような枠組みを用いることにより、受験者の能力によらない項目の困難度(や識別力など)を推定することが可能となります。そして、項目の困難度によらない受験者の能力値を推定できるのです。
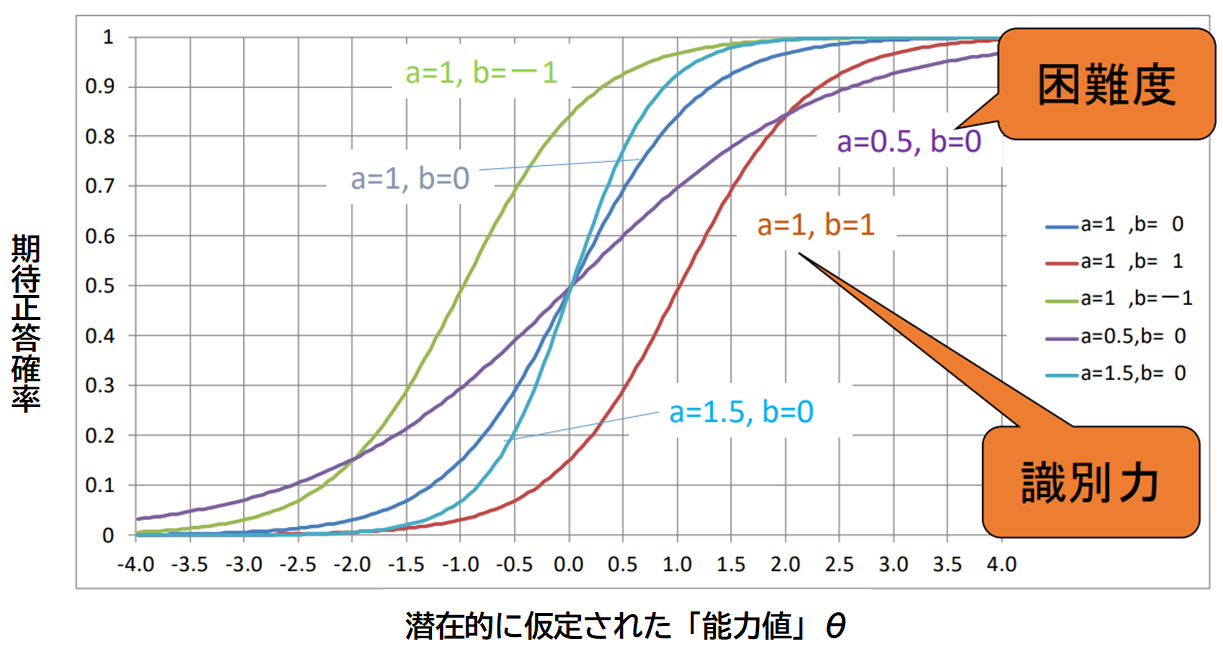
(宇佐美慧・荘島宏二郎・光永悠彦・登藤直弥, 2019を一部改変)
9. 等化(equating)
上述の枠組みにより、項目依存性はクリアできました。しかし、標本依存性をクリアできていません。複数回のテストを直接比較可能にするためには、そのテスト間で共通の項目を含ませる(非公開の同じ問題を出題する)工夫を施します。すると、その項目を手掛かりに共通のものさしを構成することが可能となり、直接比較することができるようになるのです。この操作を「等化」と呼びます。
IRTを活用したテストでは、これらの操作により、異なった受験者集団を比較したり、異なったテストを比較したりすることが可能になります。
第2回では古典的テスト理論の限界点と、それらを解決する新しいテストの評価方法である項目反応理論(IRT)について紹介しました。ここまで読んでいただいた皆さんには、IRTの特徴について理解いただけたものと思います。ただ、IRTは大規模なデータが必要であったり、問題の公表を制限する必要があったり(結果返却後に問題を見て復習することができないなど)、前の問題の答えを使って次の問題を解く大問形式の出題が難しかったり、様々な条件を満たす必要があります。そのため、実用的観点から、今でも古典的テスト理論の方が重要な役割を果たす応用場面も多いといえます。どちらの方法がよりよいかは、そのテストの目的や条件によって判断する必要があるといえるでしょう。
参考資料
- 藤永 保 (監修) (2013) 『最新心理学事典』平凡社
- 石井研究室 テスト研究(2023年4月14日時点)
- 加藤健太郎・山田剛史・川端一光(2014).『Rによる項目反応理論』オーム社
- 光永悠彦 (2017).『テストは何を測るのか』ナカニシヤ出版
- 文部科学省(2013) 中央教育審議会 高等学校教育部会(第23回)配付資料4「項目反応理論について」
- 宇佐美慧・荘島宏二郎・光永悠彦・登藤直弥 (2019).「項目反応理論(IRT)の考え方と実践-測定の質の高いテストや尺度を作成するための技術-」『教育心理学年報』58巻,p.321-329.
- 教育心理学会チュートリアル2018資料「項目反応理論(IRT)の考え方と実践」
- 埼玉県教育委員会便り号外 平成28年(2016年)3月18日発行
- 新しい横浜市学力・学習状況調査リーフレット
- 教育測定研究所:変わるテストの形態
構成・文・図:内田洋行教育総合研究所 研究員 吉中 貴信
※イラストは「ソコスト」より
※当記事のすべてのコンテンツ(文・画像等)の無断使用を禁じます。
 この記事をクリップ
この記事をクリップ クリップした記事
クリップした記事ご意見・ご要望、お待ちしています!
この記事に対する皆様のご意見、ご要望をお寄せください。今後の記事制作の参考にさせていただきます。(なお個別・個人的なご質問・ご相談等に関してはお受けいたしかねます。)
 ご意見・ご要望
ご意見・ご要望この記事に関連するおススメ記事

「教育トレンド」の最新記事